
Appleは、非常に難しいAI開発に挑戦している。それは、ユーザのプライバシーを守りながら、AIを学習させるというものだ。
学習素材として、ユーザのデータを勝手に使うようなことはしない。そこで重要になる技術が「差分プライバシー」だ。AppleのAIチームである「Machine Leaning Research」は、そのAI開発の手法の一部を公開した。
AppleのAI搭載が遅かったのには理由がある
2025年4月から、Apple Intelligenceが日本や中国、韓国などでも利用できるようになり、ほぼ世界中で使えるようになった。しかし、スマートフォンのAI対応という意味ではだいぶ後発になってしまった。
Googleは2023年10月にPixel 8 Proに「Gemini Nano」を搭載、Samsungも2024年1月に「Galaxy AI」を搭載したGalaxy S24を発売、HUAWEI、Xiaomi、OPPO、vivoなどの中国勢も2024年中にAI対応を完了している。
しかも、Googleは消しゴムマジック、Samsungはライブ翻訳という、派手で人を惹きつける機能を搭載した。iPhoneが出遅れている感は否めない。
報道ではさまざまなことが言われている。AppleのAIチームの士気が落ちているとか、Appleの技術開発力そのものが落ちているなどとするものもある。
しかし、忘れてはならないのは、AppleはAI開発をするために、非常に慎重に計画を進めているということだ。それは、ユーザのプライバシーを守るためだ。
機械学習の罠
AIは無限の可能性を秘めた技術だが、必然的にプライバシー侵害を起こしかねない側面を持っている。たとえば、多くの大規模言語モデル(LLM)が、ネット上のドキュメントを学習素材としているが、果たして、それは許されることなのか。
OpenAI社は、作家やメディアから自社のコンテンツを許諾なしで学習素材に使われたという複数の訴訟を起こされている。
つい最近話題になったGPT-4oで、スタジオジブリのアニメ作品に似せたタッチの画像を生成する遊びも、個人が遊んでいる分にはともかく、商業利用する人が出てきたらファンはやはり複雑な気持ちになるのではないか。
Appleが、メールの返事を生成してくれるAIを開発するとき、もっとも簡単なのは、実際のユーザのメール文面を学習素材としてしまうことだ。もちろん、Appleはそんなことをしない。では、どうやって、AppleはAIを開発しているのか。
“学習教材なし”に、AppleはどのようにAIを開発しているのか?
AppleのMachine Learning Researchは、その手法の一端を公開した。これを見ると、Appleがいかに苦労して、プライバシーを尊重しながらAI開発を進めているかがよくわかる。
企業などが収集した個人情報は、「匿名化することで外に出して活用することができる」という言い方では不十分で、個人情報保護法では「匿名加工情報の要件を満たす」必要があるとされている。
匿名加工情報の要件のひとつが「ほかの情報と照合しても個人を識別できないようにするための適切な加工」だ。つまり、氏名や住所といった個人が特定できない加工をした情報であっても、ほかの匿名情報と照合することで個人が識別できてしまうのはダメということだ。
AIの発展とプライバシー侵害は隣り合わせ
2006年、この問題を象徴する事件が起きた。動画配信サービスNetflixは、「Netflix Prize」という機械学習コンペを開催し、その材料として、約48万人分のユーザの視聴履歴、評価、評価日時などのデータを提供した。
もちろん、氏名などは匿名化され、個人が特定できない加工がしてある。機械学習コンペにダミーデータではなく実データを提供するのは、AIの発展にとって大きな貢献となる。
ところがテキサス大学の研究者が、IMDb(インターネット映画データベース)の公開データと照合することで、個人を再識別できることを指摘して問題となった。
鍵は、Netflixで映画の評価をし、そのままIMDbでも評価を記入する人が多かったことだ。評価した映画のリストと評価日時から、Netflixの匿名化された個人とIMDbのアカウントの多くが照合できた。
IMDbのアカウントは実名ではないために、多くの人が政治的嗜好や性的な嗜好まで書き込む。個人情報を把握しているNetflixは、自社の会員がどのような嗜好を持っているかをIMDbのアカウントと照合させることで把握できてしまう状態になっていた。
この問題は、2009年に訴訟となった。Netflix側は、原告と和解し、予定をしていた「Netflix Prize」を中止した。
全体の統計値から個人情報を逆算する「推論攻撃」
また、推論攻撃と呼ばれる手法もある。たとえば、あるスタートアップ企業が自社サイトに「弊社の従業員は10人で、平均年収は428万円です」という記述をしていたとする。
個人の収入ではなく、全体の統計値を公開しているだけなので、特に問題は感じない。
しかし、翌年、1人が離職したために「弊社の従業員は9人で、平均年収は382万円です」に修正したとしよう。
修正前後の情報があれば、離職した人の年収を計算することは簡単だ。以前の総年収から現在の総年収を引けば、離職した人の年収になる。
計算は「428×10-382×9=842(万円)」となり、しかも平均年収よりもかなり高めであることから、キーパーソンが離職したのではないかということまで推測できてしまう。
推論攻撃を防ぐ「差分プライバシー」とは?
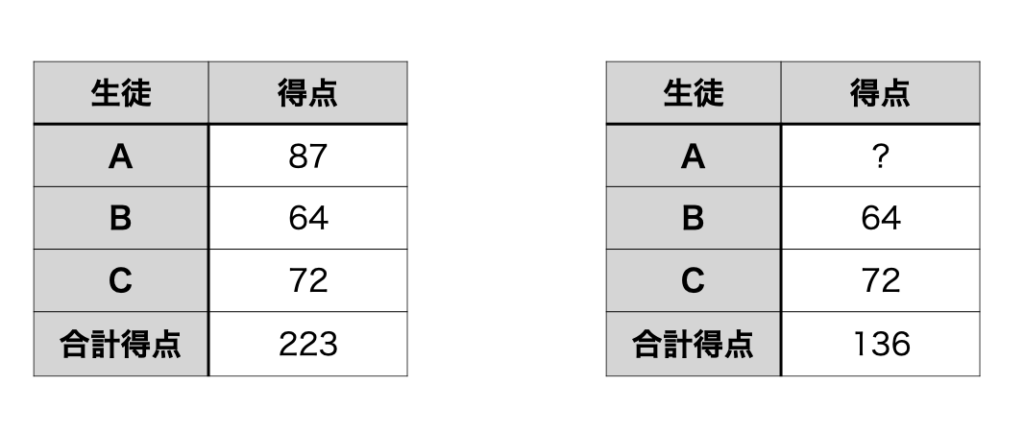
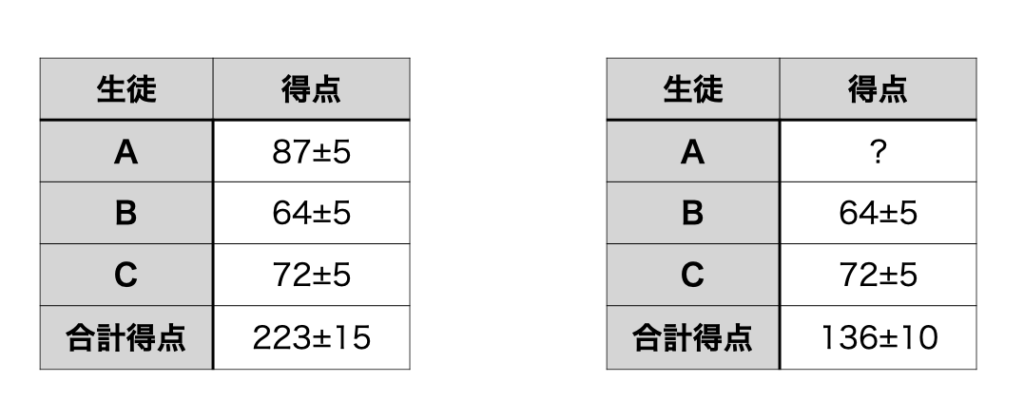
このような推論攻撃を防ぐのが差分プライバシーだ。今、3人の試験の得点がわかっていて、個人の得点は非公開にされ、合計得点または平均得点だけが公開されているとする。
しかし、Aが抜けたBとC2人の合計得点がわかれば、Aの得点は計算できてしまう。
実際のマーケティングデータなどでは、個人のデータを取得することはできないが、年齢、地域、購入履歴などの条件による絞り込みで、特定集団の統計データを取得することができる。
これを条件を変えて何度も繰り返せば、特定の個人のデータがかなりの精度で推定できてしまう。
「差分プライバシー」でユーザのプライバシーを守る
そこで、差分プライバシーでは、個々のデータに揺らぎを与える。すると、推論攻撃をしても、Aのデータは87±5点という一定の範囲までしか絞り込むことができなくなる。
ここでは、仕組みを理解してもらうために±5点という揺らぎにしたが、実際は、統計分布の理論を使って、集団のデータは正確になるが、個人のデータを推定しようとすると誤差が大きくなるように設計されている。
このような差分プライバシーは、Appleだけでなく、Googleなど多くのテック企業が個人情報を収集する際に用い、ユーザのプライバシーを守ろうとしている。
すでに、Apple Intelligenceの「ジェン文字」や予測変換、Spotlight検索で、ユーザがどのような使い方を好むのかを、「iPhone解析を共有」をオンにしているユーザから収集する際、差分プライバシー処理を行い、個人のデータはぼやけさせながら、全体の統計データとしては正確なものが得られるということを行い、改善に活かしている。
Appleがデータ収集するときは、アカウントデータもすぐに破棄されるため、万が一、Appleからデータ漏洩が起こるようなことがあっても、個人のデータは曖昧な形でしかわからないようになっているのだ。
こだわりが詰まっている! Apple Intelligenceのメール作成機能の秘密とは?
Apple Intelligenceのメール作成機能では、さらに複雑なことをやっている。ユーザのメール文を学習素材として収集できれば話は早いのだが、Appleはそういうことはできない。
そこで、AIを使って、メール文を人工合成し、それを学習素材としているのだ。
この手法の問題は、「人工合成したメール文を実際のユーザも本当に使っているのか」がよくわからないことだ。そこで、Appleはユーザに対するアンケート調査のようなことを行う。
まず、生成AIを使って、「明日の11:30にテニスをしませんか?」というメール文をつくる。そして、このメール文の一部を変えて、バリエーションをつくる。たとえば、次のようなものだ。
- 火曜日の10:30にテニスをしませんか?
- 明日の11:30にサッカーをしませんか?
- 明日の11:30にテニスのレッスンをしませんか?
この3つのメール文のうち、どれが実際によく使われているのかを調査する。
AppleはメールのAI機能開発でさえ、メールの中身を読まない
その手法とは、メール文を「iPhone解析を共有」をオンにしているユーザに送り、実際のメール文と比較して類似度を計算する。そして、類似度がもっとも高いものを「よく使われている」と判定するのだ。
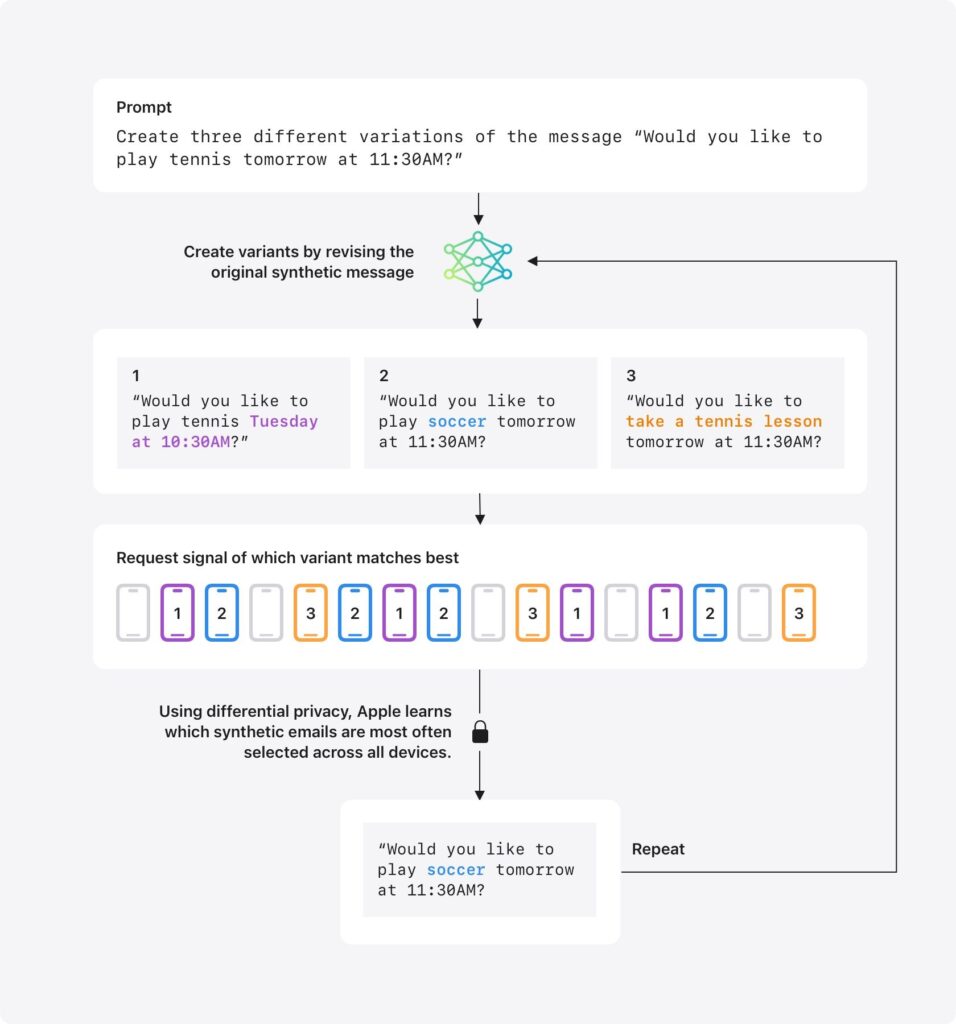
ここで注意していただきたいのは、iPhoneの中で行われるのは、Appleが送信してきたメール文と実際のメール文の類似度の計算だけで、Appleはメールの中身を読んだりしていないことだ。
そして、1から3までの中で、もっとも類似度が高い番号を、iPhoneはAppleに送信する。この時、差分プライバシーがかけられ、Appleは受け取ると同時にアカウント情報を廃棄する。
それでも全体の統計としては、どの選択肢がもっともよく使われているかをAppleは知ることができる。
プライバシーを侵害して開発されたAIは、誰だって使いたくないはず
Appleはこれを手がかりに、どのようなメール文が広く使われているかの知見を積み重ね、Apple Intelligenceを改善していく。
素人考えでも、AI開発という視点では、ものすごく遠回りな手法のように見える。開発チームは相当頭を悩ませているのではないだろうか。
しかし、そう遠くない将来、あるいは今でも、人々のプライバシーを侵害して開発されたAIは使いたくないという人々が増えていくだろう。
それは今すでに、地球の環境を破壊する利器は使いたくないと考える人がいるのと同じだ。
AppleのAI開発は、ここ1年、2年のことではなく、10年や20年といった長期視点で行われているのかもしれない。私たちも辛抱強く見守る姿勢が必要かもしれない。
おすすめの記事



著者プロフィール

牧野武文
フリーライター/ITジャーナリスト。ITビジネスやテクノロジーについて、消費者や生活者の視点からやさしく解説することに定評がある。IT関連書を中心に「玩具」「ゲーム」「文学」など、さまざまなジャンルの書籍を幅広く執筆。



