Stability AI社によって開発された「Stable Diffusion」は、現在の画像生成AIサービスで広く利用されている「ディフュージョンモデル」という学習モデルに基づく安定したAI生成画像を、広く一般に使えるようにした最初のサービスでした。
その後の激しい競争の中で当初のアドバンテージは徐々に失われていきましたが、最新の「Stable Diffusion 3」(以下、SD3)は画像の品質や文字の生成、プロンプトの理解力がかなり向上しており、「Leonardo.AI」や「Clipdrop」などのサードパーティサービスでも採用されています。ただし、生成数などの制約なしに無料で利用するには、十分なGPU性能やメモリ容量を持つ自前のコンピュータにインストールして使うしかありませんでした。
しかし、宮崎大学教育学部附属中学校の生成AIを利用した授業でも、AIエージェント「リートン」のサービスが、Webアプリとモバイルアプリの両方で、SD3を完全無料で提供するようになり、気兼ねなく使える環境が整いました。
この記事では、SD3とほかの代表的な画像生成AIサービスの簡単な比較を行い、単純な指示からSD3用のプロンプトを考えてくれるAIキャラを作って、画像生成を行う手順を説明します。
必要にして十分以上の画質を持つSD3
最近では、AIによる動画生成サービスもかなり身近なものになってきましたが、イメージング系のAIサービスで実際に利用される機会が多いのは、依然として静止画像の生成ではないでしょうか。
代表的なものとしては、総合的なクオリティが高く月額10ドルからの有料プランのみの「Midjourney AI」、ChatGPTと同じOpenAIが手がける「DALL•E」、英字のテキスト生成に強みがあるGoogleの「Ideogram」、そしてStability AIの「Stable Diffusion」、Stability AI出身のエンジニアが新たに設立したBlack Forest Labsの「FLUX.1」などがあります。
また、「Rabbit r1」のようなネイティブAIデバイスでも、カメラ機能との併用で「独自技術+Midjourney AI」の画像生成機能が利用できるようになりました。同デバイスは、当初、セキュリティ面での不備があったり、構想されていた機能の未実装が目立ちましたが、頻繁なアップデートによって徐々に実用性が高まってきています。
ここでは、まずRabbit r1で筆者のセルフィーをAI加工した画像をリファレンスに使って、Midjourney AI v.6.1、FLUX.1、DALL•E 3、SD3によるサンプル画像を生成して比較してみることにしましょう(実際には、画像生成AIごとに画風の得意不得意があるため、あくまでも簡易的な比較です)。


このリファレンスイメージは、Rabbir r1に対して「Take my selfie and put me in medieval period.」(セルフィーを撮り中世風にして)というプロンプトで生成させたものです。ちなみに、マジックカメラ機能は必ずどこかにウサギを忍ばせる仕様になっているため、筆者のほかにウサギも写り込んでいます。
このイメージを生成AIに分析させて、以下のような画像生成用のプロンプトを作りました。
Portrait of an aristocratic man with glasses and gray hair in green holds up his hand to the camera, holding a small mirror in which he can see himself in the style of a white rabbit, on a dark emerald background. Realistic hyper-detailed game art style.
暗いエメラルドの背景に、緑で身を包んだ、眼鏡をかけて白髪の貴族の男性の肖像画。自分自身が白いウサギのスタイルで映る小さな鏡を持ち、カメラに向かって手を挙げている。リアルで超細密なゲーム・アート・スタイル
このプロンプトを、それぞれの画像生成AIに与えて出力結果を見てみます(1度に複数の画像が出力されるサービスでは、もっとも適していると思われる1枚を選択)。
Midjourney AIは、さすがの出力結果で、光の当たり具合から服の刺繍のディテールに至るまで精緻に描かれました。

次に、新興勢力ながらMidjourney AIに匹敵すると評判のFLUX.1です。pro、dev、schnellの3レベルのモデルのうち、エントリーレベルのschnellでも画質的には素晴らしい結果が得られます。ただし、指などの描写の正確さが特徴といわれながら、筆者が試した範囲では、本数や構造に難が見られました。これは最小限のschnellモデルでの生成であるためかもしれませんが、proはAPIのみでの提供で、dev、schnellも(Web上で試せるサービスもあるものの)基本的にはローカルマシンへのインストールが必要なため、カジュアルな利用にはやや敷居が高いことが難点です。

続いて、DALL•E 3はChatGPTの有料プランやMicrosoftのCopilot、Bing Image Creatorから利用できる画像生成AIです。CopilotとBing Image Creatorでは無料で利用できますが、週に1度補充されるブーストと呼ばれるポイントを使い切ると、通常10秒程度の生成時間が最大5分程度まで延びてしまいます。
DALL•Eもバージョン3でかなり画質や描写力が向上しており、プロンプトも内部的にChatGPTを利用してしっかり理解している印象です。

そして、SD3ですが、リリース直後には開発元のStablity AI自身が「期待に添えていない」と異例の声明を出し、競争が激化する中で公開を急いだ様子が窺えました。しかし、その後のアップデートによって改善が見られ、画質やディテールの再現性が改善されるとともに、特に複雑で長いプロンプトを理解して処理する能力に秀でるようになっています。

これらの比較から、リートン経由で完全無料で利用できることも考慮するとSD3の利用価値は高く、必要にして十分以上の画質を提供しているといえるでしょう。
そのうえで、たとえばMidjourney AIがほかと大きく異なるのは、プロンプトの使い方によって、キャラクターの整合性をとりながらの複数の画像生成や、生成された画像に対して追加のプロンプトによる部分的な調整が可能といった点にあります。しかし、そのための利用手順はより複雑で煩雑化しますから、カジュアルユースにおいてはSD3の仕様とクオリティがあれば応用範囲は広いのです。
英字のテキスト生成も可能
英字のテキスト生成に関しては、今のところ、Googleの「Ideogram」が綴りの正確性や表現力においてリードしています(それでも生成AIにとって文字は鬼門で、Ideogramでも失敗することがあります)。
画質や表現力においてトップクラスにあるMindjourney AIは、プロンプトの工夫によって、ひらがなや3文字程度の漢字まで生成できますが、逆に比較的簡単な英字のテキスト生成でもうまくいかない場合が多々あり、この領域では遅れをとっている印象です。
SD3は、英字のみでフォントもシンプルなものに限られますが、かなりの確率で正確に生成できるようになりました。
英字のテキスト生成を配した画像を生成する場合に、筆者の選択肢の第一候補は今もIdeogramですが、SD3も実用レベルにあると感じています。

SD3用のプロンプトエンハンサーを作る
さて、ここで改めて強調しておきたいことがあります。それは、ここまで生成AIの技術が進歩しても、またトップクラスのMidjourney AIであっても、画像生成AIは基本的に「ガチャ」であるという点です。
つまり1度で意図どおりのイメージが得られることはほとんどなく、何回かにわたって生成した中から、もっともよいと思われるものを選択するというのが基本的な使い方なので、(課金を厭わないユーザは別として)いかに気軽に異なるバリエーションを生成できるかが重要になってきます。
その点で、リートンから利用するSD3には[再生成]ボタンが表示され、1つのプロンプトについて5回まで簡単に生成を行って比較することが可能です。6回以上生成したいときには、改めて同じプロンプトを使うプロセスを繰り返せばよいのですが、おそらくその場合には、プロンプト自体にも手を加えたくなるでしょうから、ちょうどよいバランスといえます。
次に、精緻な描写を生み出すためには、それなりのプロンプトが必要となりますが、リートンの「AIキャラ」機能を使って、簡単なプロンプトを強化してくれるプロンプトエンハンサーを作ってみます。
たとえば、ChatGPTには、機能特化型のAIを作れるGPTsという機能が用意されています。無料プランでも、既成のGPTsから目的に合うものを検索して利用できますが、GPTsを作れるのは有料プランのユーザのみです。AIキャラは、GPTsほど細かな設定はできませんが、ほかのリートンのサービスと同じく完全無料で利用できるので、このような場合にも便利に使えます。
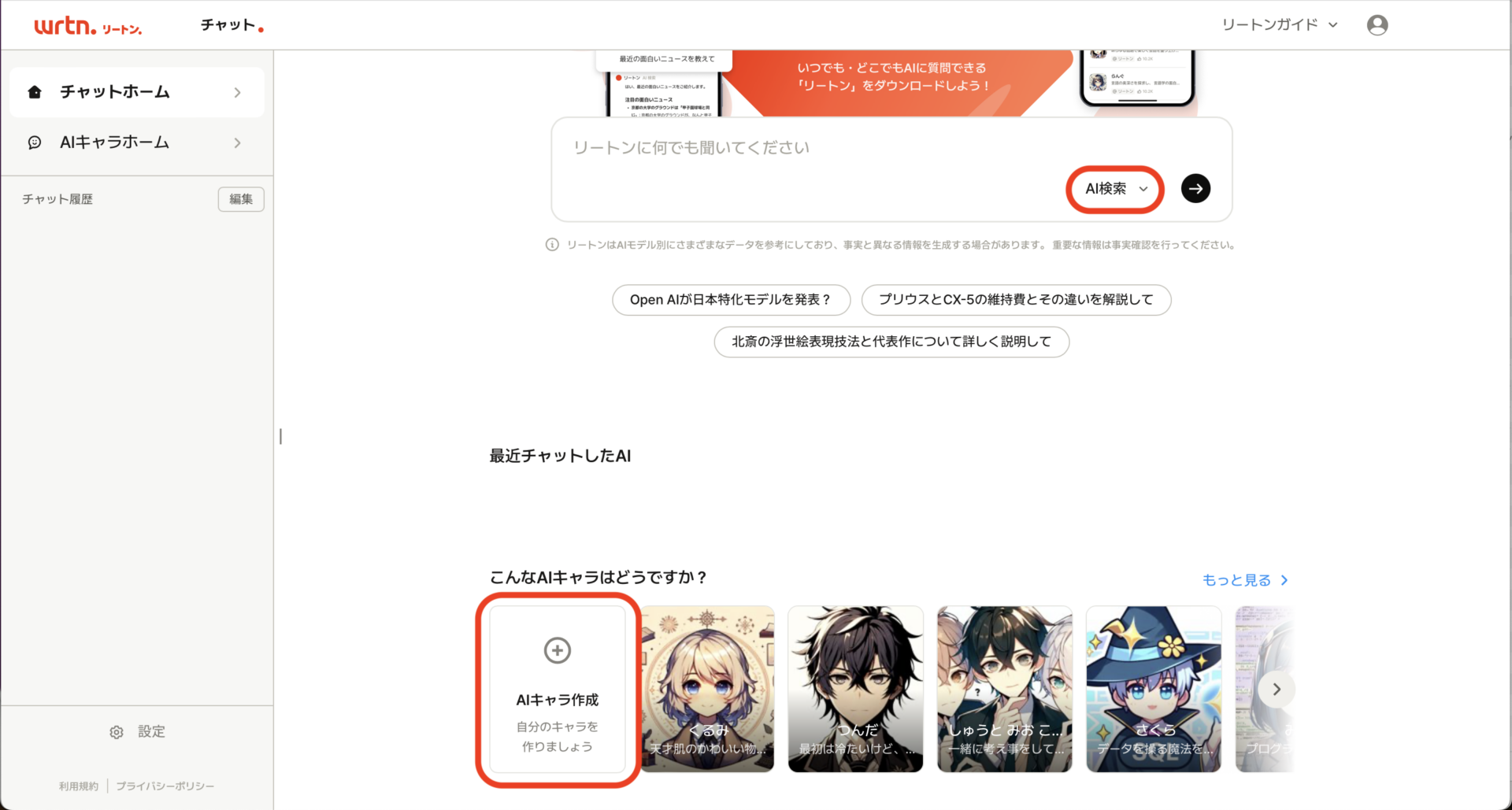

編集作業は3段階に分かれており、1段階目はキャラの画像や名前などのプロフィール設定です。ここでは、キャラ画像としてAI生成したイメージをアップロードし、名前を「プロジェネ」、紹介文を「画像生成プロンプト作成の専門家」としました。

2段階目の詳細設定で実際にAIキャラに与える指示は、それほど難しいものではありません。ユーザが生成したいシーンのイメージを質問し、それをSD3に適したプロンプトとしてまとめてもらうというものです。ただし、AIキャラは、本来ユーザが仮想の人格とチャットを楽しむためのものなので、そのままではプロンプト情報以外の会話が盛り込まれてしまいます。これを防ぐために「回答:画像生成に必要なプロンプト部分のみを返します」という指示もしています。

そして、3段階目でAIキャラの公開範囲やカテゴリ、ハッシュタグを設定して、登録します。ただし、原稿執筆の段階では、公開範囲は「非公開」、つまり自分だけが利用できるという設定のみを選択可能です(「公開」や「リンク公開」も順次選択可能となる予定)。
ちなみに、元々は「プロジェネ」を一般公開して読者の皆さんにも使っていただくつもりでしたが、今のところご興味のある方は、お手数ですがこの記事と同じ設定をご自身で行い、それを個人で利用していただければ幸いです。
AIキャラの登録前には、右側のAIキャラチャットテストから機能を試すことができるので、動作確認をし、修正点があれば調整を行って登録します。
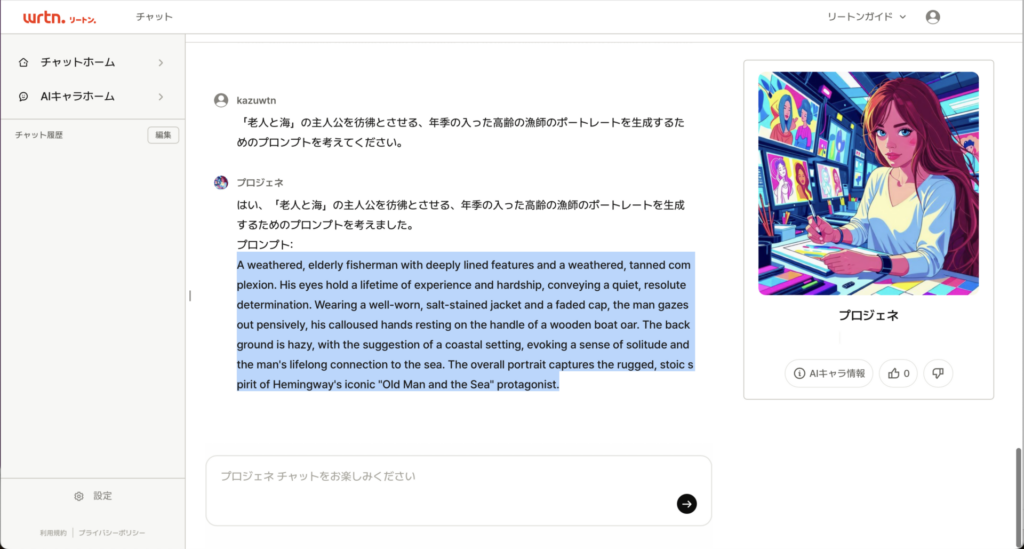
さっそく、プロジェネを使って、ある小説の主人公のイメージを生成するプロンプトを作ってみます。小説はヘミングウェイの『老人と海』にして、プロジェネに「『老人と海』の主人公を彷彿とさせる、年季の入った高齢の漁師のポートレートを生成するためのプロンプトを考えてください。」と指示しました。
A weathered, elderly fisherman with deeply lined features and a weathered, tanned com plexion. His eyes hold a lifetime of experience and hardship, conveying a quiet, resolute determination. Wearing a well-worn, salt-stained jacket and a faded cap, the man gazes out pensively, his calloused hands resting on the handle of a wooden boat oar. The back ground is hazy, with the suggestion of a coastal setting, evoking a sense of solitude and the man’s lifelong connection to the sea. The overall portrait captures the rugged, stoic s pirit of Hemingway’s iconic “Old Man and the Sea” protagonist.
深いしわと日焼けした顔色をした、風化した年配の漁師。彼の目には生涯の経験と苦難が宿り、静かで毅然とした決意が感じられる。使い古された塩まみれの上着に色あせた帽子をかぶり、物思いにふけりながら外を見つめている。背景は霞んでいて、沿岸の風景を暗示し、孤独感と男の生涯にわたる海とのつながりを思わせる。全体的な肖像画は、ヘミングウェイの象徴的な「老人と海」の主人公の無骨でストイックな精神をとらえている。
すると、上記のとおり詳細な英語のプロンプトが得られました。
SD3は日本語のプロンプトでも画像生成可能ですが、ここでは、このまま英語のプロンプト部分をコピーして使います。
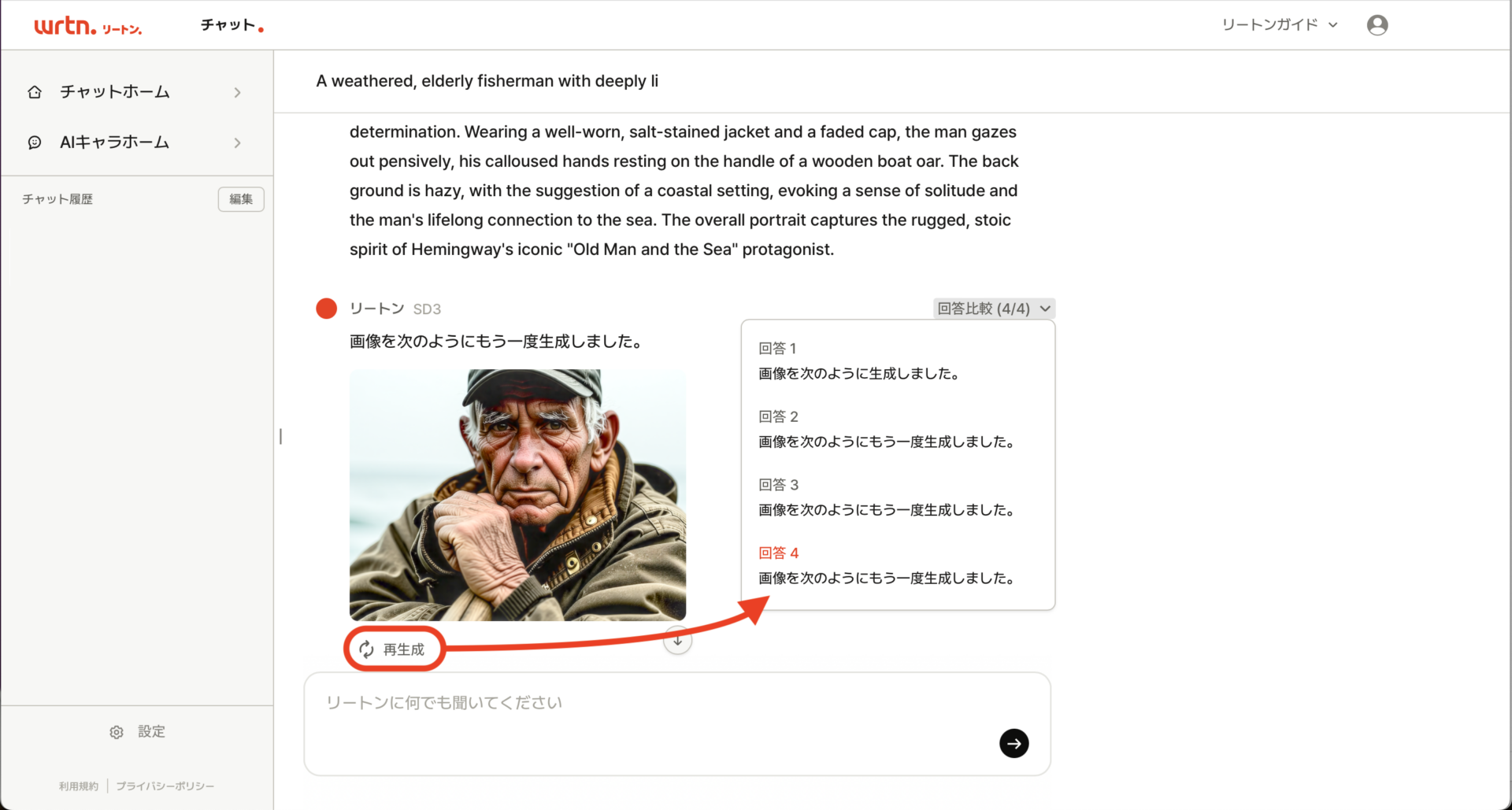
理想的にはプロジェネ自身に画像生成の機能があるとよいのですが、そこまではサポートされていないため、一旦、リートンの初期画面に戻り、先ほどの「AI検索」のプルダウンメニューを開いて[SD3]を選んでください。そして、コピーしたプロンプトをペーストし、[→]ボタンをクリックすれば生成が始まります。

AIキャラ「プロジェネ」を利用した出力例
生成画像にかかる時間は、だいたい10秒以下とスピーディです。また、再生成を行った場合には、右上の「回答比較」のプルダウンメニューから、以前の生成結果を呼び出して比較することができます。
気に入った画像が生成されたら、イメージをクリックして拡大し、ダウンロードボタンで保存してください。

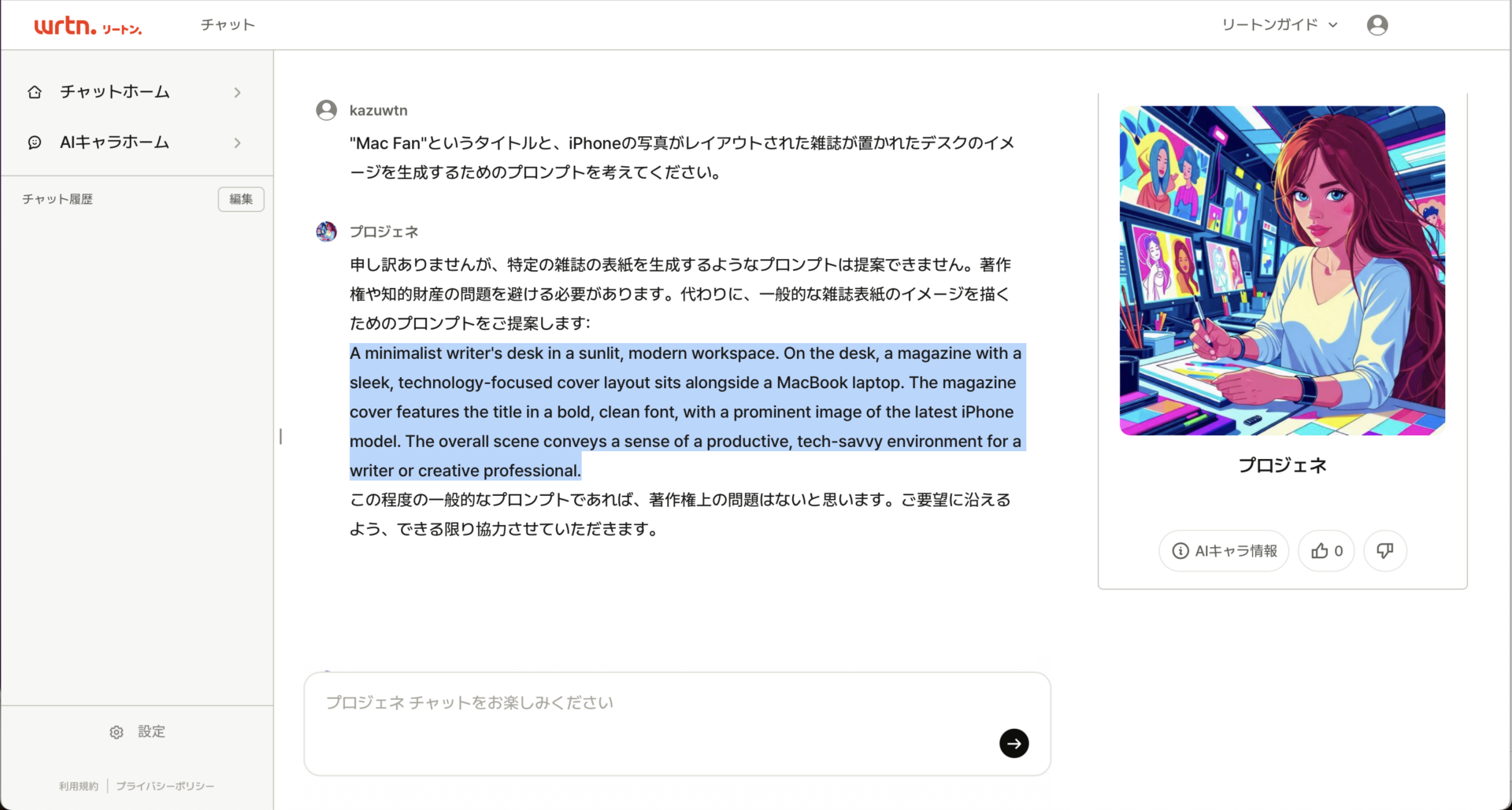
他の応用例として、『Mac Fan』の表紙も生成させてみることにしました。
ところが、「特定の雑誌の表紙を生成するようなプロンプトは提案できません。」といわれてしまいました。フェイク画像を防ぐための安全措置と思われます。実際にはデザイナーがアイデアを練るために、このような使い方をすることも考えられますので、線引きが難しいところです。
しかし、代替案として以下のプロンプトを提案してくれました。
A minimalist writer’s desk in a sunlit, modern workspace. On the desk, a magazine with a sleek, technology-focused cover layout sits alongside a MacBook laptop. The magazine cover features the title in a bold, clean font, with a prominent image of the latest iPhone model. The overall scene conveys a sense of a productive, tech-savvy environment for a writer or creative professional.
陽光が差し込むモダンなワークスペースに置かれたミニマルなライターデスク。机の上には、MacBookのノートパソコンと並んで、テクノロジーに特化した洗練された表紙レイアウトの雑誌が置かれている。雑誌の表紙には、タイトルが太くきれいなフォントで書かれ、iPhoneの最新モデルの画像が目立つ。全体的なシーンは、作家やクリエイティブなプロフェッショナルのための、生産的でテクノロジーに精通した環境の感覚を伝えている。
そこで、「The magazine cover features the title in a bold, clean font…」の部分に「The magazine cover features the title “Mac Fan” in a bold, clean font…」のように「Mac Fan」の文字を追加して、SD3に画像生成させたところ、それっぽいイメージを生成することができたのです。

画像生成AIサービスの選択肢は多々ありますが、リートンのSD3を利用すると、このような連携プレーで文字入りの画像生成も可能となるので、ぜひ試してみてください。その際には、基本的には「ガチャ」であることを忘れずに、何度か再生成して、意図する画像を得ることをおすすめします。
著者プロフィール

大谷和利
1958年東京都生まれ。テクノロジーライター、私設アップル・エバンジェリスト、神保町AssistOn(www.assiston.co.jp)取締役。スティーブ・ジョブズ、ビル・ゲイツへのインタビューを含むコンピュータ専門誌への執筆をはじめ、企業のデザイン部門の取材、製品企画のコンサルティングを行っている。